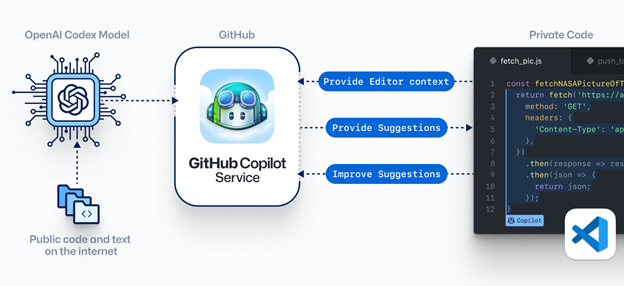
E-learning or as some prefer to rebrand it – digital learning is a well-known category of solutions that fulfills the role of educating, using a computer in some way. Okay, we’ve got the definition covered, let’s move on.
So, as an owner of a company, or a manager, what should you know about it?
Why in the first place?
The simplest answer – ignoring all other whys – traditional courses are more expensive. You can send off an employee to a “MOOC” like Udemy to self-educate, for much cheaper than providing them with actual instructors. You give them access to courses, and everyone is happy, employees are growing, and you’re paying not much, right? This is partly what our university is doing, offering LinkedIn Learning rather than providing an insane amount of opt-in courses that would require massive scale to work.

But hold on, it’s not that easy. You’ve just paid for access to courses to your employees and they’re not touching them. It might be a problem with your organization, its culture, or it’s a problem with you.
For example – some corporations choose to opt-in for learning Fridays (aside from other fancy Friday options). The problem with that is the learning time often is 2pm, Friday. What a great time for learning! What about employees leaving the subscription running? Well, some employers choose to opt-in for co-financed courses. You’re learning English online, but you’re paying for half of it, so you’re not wasting our money. I’m not going to analyze whether it’s a good or a bad solution here.
Big brother

So, the problem you’ve probably now noticed is – accountability in e-learning. Lack of real human interaction, no external force (if you don’t impose some requirements on your employee) (by the way – gamification might be a fun way to boost some of your employee’s motivation), and lack of predefined learning time, makes it hard for people to be accountable with their learning goals. That’s why one of the more important functions you have in Learning Management Systems is reporting.
Learning Management what?
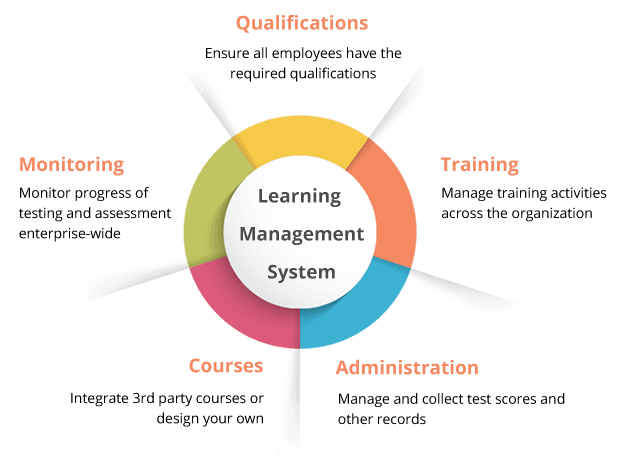
Learning Management System is a kind of software that’s designed to manage all of learning. From delivery of courses – by a website/app to administration. One of the most popular platforms, particularly in the world of universities is Moodle. It’s free and open-source, and you just have to pay for extensions from the store. There’s also plenty of other cloud options, starting with Docebo, Blackboard, Easy LMS, 360 Learning, and so on… They provide powerful options for most corporate users. They are slightly less customizable, not that you need to customize that much, they are giant machines (with the exclusion of Easy LMS – its point is simplicity) with hundreds of options. That sounds great, however, when it comes to money, it’s not the best deal. If you’re to be stingy, 4-12$/employee is not the best deal, for something that’s not deeply customizable. That’s where custom made LMS’es come in. Okay, you’ve got the LMS, now what?
Courses.

Courses, you can create them by yourself, or buy them. Now, a lot of LMSes come already with a sizeable portfolio of pre-made courses. However, they’re not really made for you. You can choose to create your own courses, which can prove to be expensive. According to skilldlabs.com – it takes 80 to 280 hours to develop a 1-hour course. That’s why a lot of platforms put pressure on making course creation/prototyping as fast as possible. You don’t want to create and your LMS provider doesn’t have what you want? You can buy off-the-shelf courses. New LMSes are supposed to integrate with a multitude of platforms like OpenSesame. If you’re a dinosaur, you might want to use SCORM though. It’s an age-old technology, a static zip-file with JavaScript in it, that communicates with your server’s API. That way, you can place SCORM truly, anywhere. You can also make a course in SCORM then place it in almost any LMS.
But I don’t want to own!
Sure, then go with LinkedIn Learning, or if you work in IT – Pluralsight. It’s a great choice, though a bit pricey. But as they say – the true value of education is intangible.
Counting numbers

Okay, you’ve got your happy employees learning from your curated list of content. Now, here’s the tough part. Do they actually learn? What they learn makes you money? That’s where reporting comes in. What does it do? You can measure multiple things, starting from simple course completion, ending at the hardest measure of all – impact on performance in the organization. Even though a course is liked, and completed by many, is it valuable to the company? It’s a difficult question that can’t be easily answered with numbers, and often numbers will yield fallacious results – as there are too many variables.
This is where we end our school trip, I hope you, have found this read useful to you, cheers!
Sources:
skilldlabs.com – How much does it cost to develop an online course in 2021? Lachezar Arabadzhiev
360factors – LMS picture