
Machine learning is able to do many things as long as we have data to teach our model. Because of this, researchers are trying to make algorithms smarter and smarter and no longer need so much information to learn. Facebook as a huge collection of images is the perfect place to do research on this topic and improve algorithms. The main goal of the research is to teach the algorithm, so that the computer vision becomes self-steering, so to speak.

Semi-supervised learning is not all that easy because at the current stage of development, algorithms can fill in data gaps by extracting information only from training sets. While this is fairly easy for text analysis, it is much more difficult for images and video. This is due to the fact that text is quite repetitive. Sentence structure and words are repetitive. In contrast, objects seen in images are much more varied. Other colors, objects, and surroundings are much more difficult to recognize than text. While this is not an easy task, the investigators have shown that it is possible and produces very visible results.

The DINO system is able to learn to find interesting objects in videos depicting people, animals and objects quite well without any labelled data. It achieves this by treating the video not as a sequence of images to be analyzed one by one. By paying attention to the middle and end of the video, as well as the beginning, the agent can get a sense of things like “an object with this general shape goes from left to right.” This information is used in other knowledge, e.g. when the object on the right overlaps the first object, the system knows that they are not the same thing, they are just touching each other in those frames. This knowledge in turn can be applied to other situations. In other words, the system develops a basic sense of visual meaning and does so with very little training on new objects.
https://www.digitaltrends.com/features/facebook-ai-image-recognition/



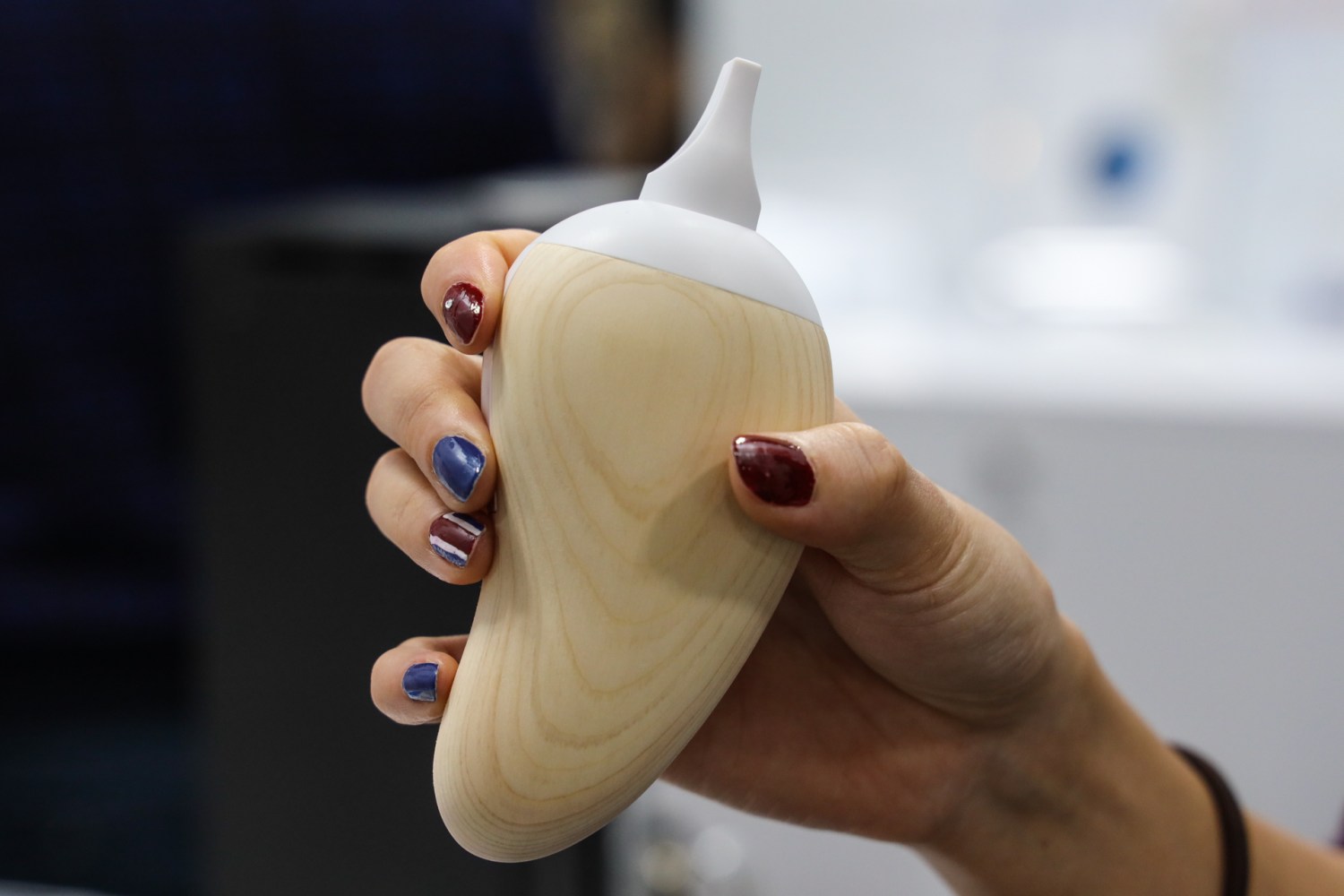 Kitoki looks like a larger irregular egg, with the white mouthpiece on one end. It is rather weird looking but has a precisely suited cedar chassis.
Kitoki looks like a larger irregular egg, with the white mouthpiece on one end. It is rather weird looking but has a precisely suited cedar chassis.


/https%3A%2F%2Fblueprint-api-production.s3.amazonaws.com%2Fuploads%2Fcard%2Fimage%2F903276%2Fcf78e4da-4256-45ba-bd1c-020f58c183f5.jpg)



{kind=link}
{kind=link}