
INTRODUCTION
Crypto assets are no longer on the fringe of the financial system.
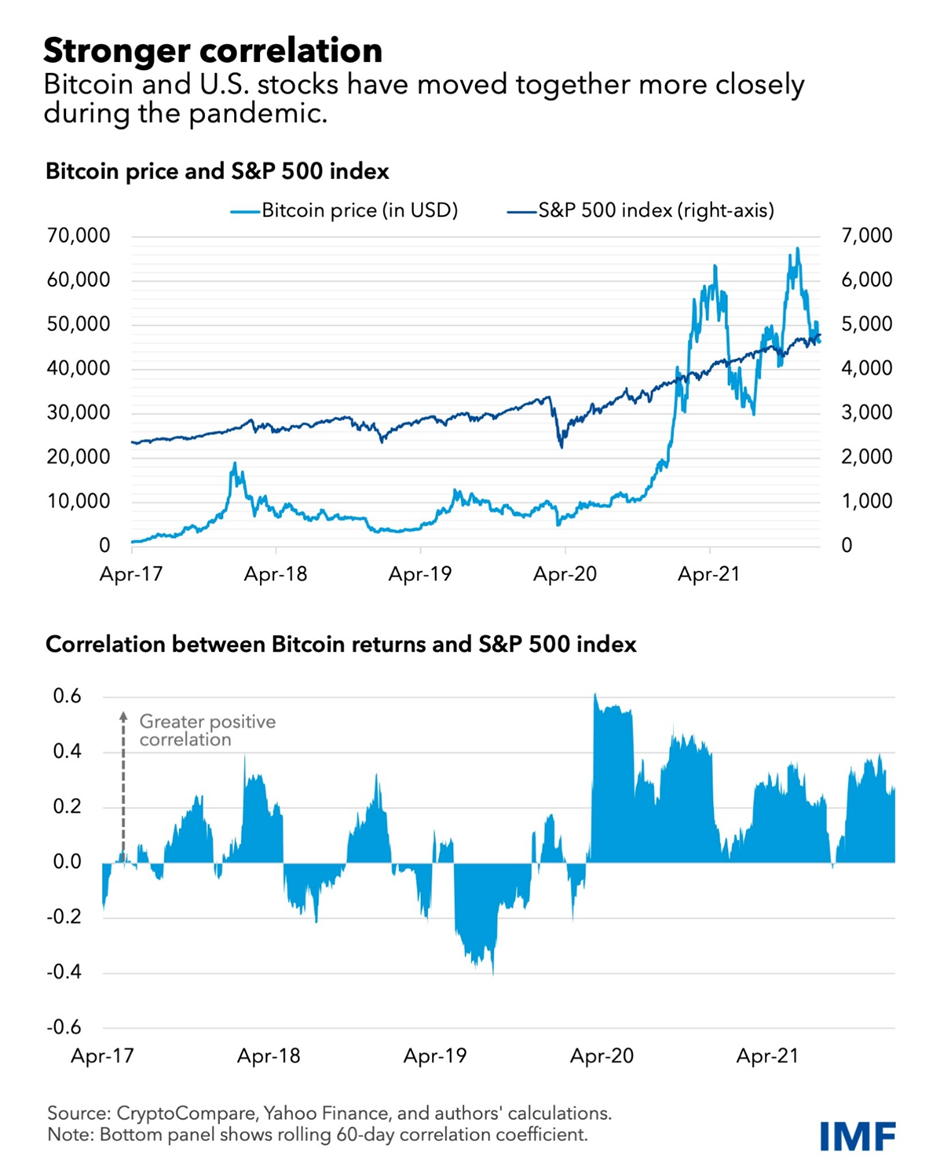
The market value of these novel assets rose to nearly $3 trillion in November from $620 billion in 2017, on soaring popularity among retail and institutional investors alike, despite high volatility. This week, the combined market capitalisation had retreated to about $2 trillion, representing an almost four-fold increase since 2017.

Amid greater adoption, the correlation of crypto assets with traditional holdings like stocks has increased significantly, which limits their perceived risk diversification benefits and raises the risk of contagion across financial markets.
The stronger association between crypto and equities is also apparent in emerging market economies, several of which have led the way in crypto-asset adoption between returns on the MSCI emerging markets index and Bitcoin was 0.34 in 2020–21, a 17-fold increase from the preceding years.
Stronger correlations suggest that Bitcoin has been acting as a risky asset. Its correlation with stocks has turned higher than that between stocks and other assets such as gold, investment grade bonds, and major currencies, pointing to limited risk diversification benefits in contrast to what was initially perceived.
Crypto assets have experienced tremendous growth over the past two decades, with the number of coins increasing from just Bitcoin in 2009 to over 5,000 currently, and reaching a total market capitalization of over USD 3 trillion towards the end of 2021. However, this growth has been accompanied by significant volatility, with most crypto coins going through several cycles of rapid growth followed by dramatic collapses. This is reminiscent of other periods in financial history in which private forms of money have proliferated in the absence of adequate government regulation, leading to frequent financial crises (such as in the US during the “Free Banking Era” of 1837–1863).
The rapid ascent of crypto assets, coupled with their increasing mainstream adoption, has generated concerns among policymakers and regulators, who are mindful about the potential contagion risks to other financial markets as well as the broader macro-financial. Crypto asset markets can both act as a source of shocks or as amplifiers of overall market volatility, thereby having the potential to have significant implications for financial stability. Consequently, policymakers face an imperative to enhance their comprehension of the interconnections between crypto assets and financial markets, enabling them to devise regulatory frameworks that effectively counteract the potential adverse consequences of crypto assets on financial stability.
The complex and rapidly evolving nature of the crypto market pose challenges for regulators in effectively assessing and addressing associated risks. Crypto assets encompass a wide range of technological attributes and features, serving means of payment, to store of value, speculative asset, support for smart contracts, fundraising, asset transfer, decentralized finance, privacy, digital identity, governance, among others. However, their relationship with traditional financial assets, particularly in terms of diversification potential, remains a subject of debate. While substantial research has investigated the nature, direction and intensity of linkages between crypto assets and crypto assets and other financial assets, the findings are still relatively inconclusive and paint a complex picture of interdependencies.
The multifaceted interaction channels between crypto assets and financial markets may make it challenging to assess the relationship, while it may also have changed over time.
On the one hand, a “fight-to-safety channel” would suggest that investors may allocate their funds into crypto assets during periods of economic uncertainty or market stress if cryptos are perceived as safer and offering a good hedge to certain financial assets. Crypto assets can thus provide diversification benefits if their correlation with certain classes of traditional assets is low. However, their tendency for high volatility raises important concerns. Another potential channel is the “speculative demand channel”, which would suggest that demand for crypto assets may increase during times of high financial market risk appetite, as cryptos offer the potential for high returns due to their volatility. Further channels could be related to market liquidity and to information spillovers or investor sentiment, which can lead to additional comovement between various classes of financial assets and crypto markets.
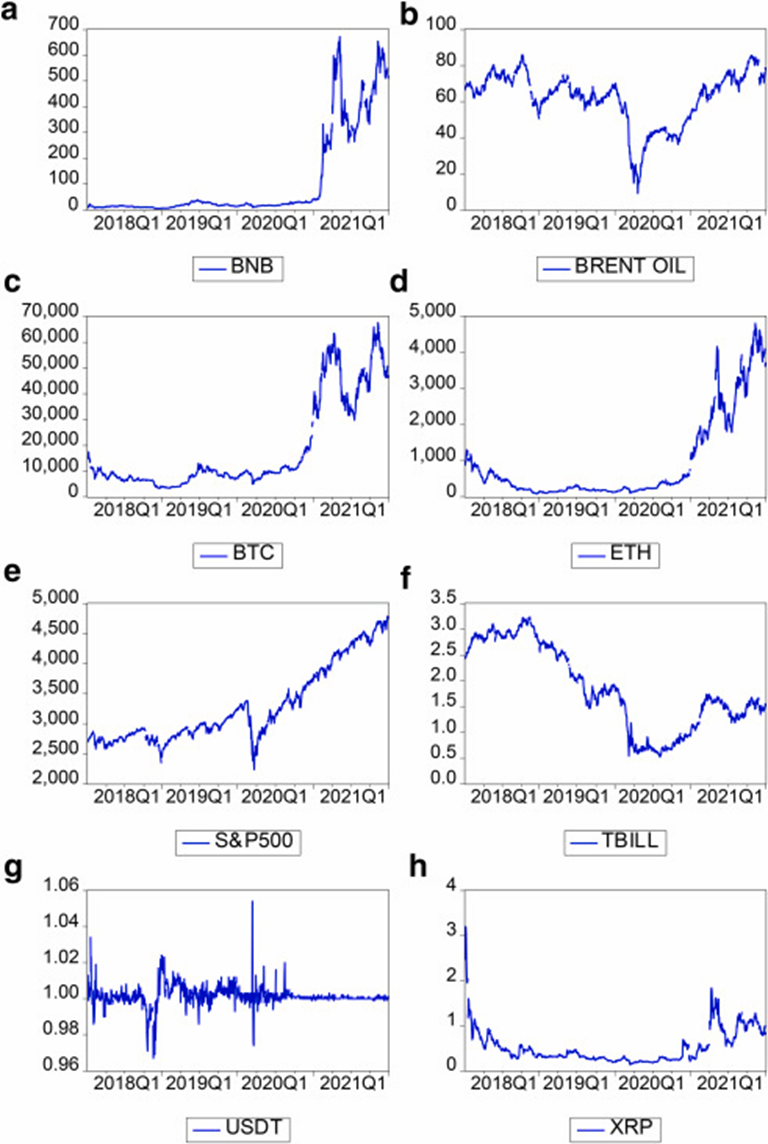
This dataset consists of the daily closing price of the five largest crypto assets by market capitalization namely Bitcoin (BTC), Ethereum (ETH), Ripple (XRP), Binance (BNB), and Tether (USDT) as of December 31st, 2021. The stock market is captured by the US S&P500 index, and we also include the Brent oil price, as well as the 10-year U.S. treasury bill as control variables to account for the possible impact of variations in commodity prices and financial condition on asset prices. The US S&P500 tracks the performance of 500 large companies in leading industries and represents a broad cross-section of the U.S. economy and is widely considered representative of the overall stock market . Tether (USDT) is a stable coin used in this study to provide insight into the inflow and outflow of funds in the market and as a tool for hedging against the volatility of the crypto market. For this reason, the USDT is likely to be more sensitive to the movement of price in the crypto market. presents a time series plot of the sampled variables. The daily datasets are in U.S. dollar currency and span from the period January 2018 to December 2021, excluding non-trading days for uniformity. Data on cryptocurrencies (Bitcoin, Ethereum, Ripple, Binance, and Tether) were retrieved from Yahoo Finance, whereas data on Brent oil, and U.S. 10-year treasury bills were retrieved from the U.S. Federal Reserve Bank of St. Louis. Additionally, the U.S. S&P500 was retrieved from Investing market indices. The baseline specification of this study considers the S&P500 index as an endogenous variable whereas cryptocurrencies and the control variables are used as dependent variables.
The increased and sizeable co-movement and spillovers between crypto and equity markets indicate a growing interconnectedness between the two asset classes that permits the transmission of shocks that can destabilise financial markets.
CONCLUSION
This analysis suggests that crypto assets are no longer on the fringe of the financial system, IMF said.
The market value of these novel assets rose to nearly $3 trillion in November from $620 billion in 2017, on soaring popularity among retail and institutional investors alike, despite high volatility. This week, the combined market capitalization had retreated to about $2 trillion, still representing an almost four-fold increase since 2017.
Amid greater adoption, the correlation of crypto assets with traditional holdings like stocks has increased significantly, which limits their perceived risk diversification benefits and raises the risk of contagion across financial markets, according to new IMF research.
By- Shannul Mawlong 50401
AI Sources: chat gpt 4
Other sources: https://www.business-standard.com/article/markets/crypto-prices-moving-in-sync-with-stocks-posing-systemic-risks-122011200477_1.html






