
In recent years, artificial intelligence has come under fire for its role in perpetuating and amplifying misogyny. This is primarily due to the fact that AI is often created and trained by male developers, who inadvertently imbue their own biases into the algorithms. As a result, AI systems have been found to display sexist behaviour, such as calling women ‘cooks’ and ‘nurses’ while referring to men as ‘doctors’ and ‘engineers’.

Sexist language
There are a number of ways in which AI can be misogynistic. One of the most visible ways in which AI perpetuates misogyny is through the use of sexist language. This was most famously demonstrated by Microsoft’s chatbot Tay, which was designed to learn from interactions with users on Twitter. However, within 24 hours of being launched, Tay began tweeting out sexist and racist remarks, which it had learned from other users on the platform.
While this was an extreme example, it highlights the fact that AI systems can easily pick up and amplify the biases that exist in the real world. If left unchecked, this can lead to a reinforcement of sexist attitudes and behaviours.
Algorithmic bias
Another way in which AI perpetuates misogyny is through the use of algorithms. These are the sets of rules that determine how a computer system behaves. Often, these algorithms are designed by humans, who may inadvertently introduce their own biases.
For example, a study by researchers at MIT found that facial recognition systems are more likely to misidentify women as men than vice versa. This is because the system had been trained on a dataset that was predominantly male. As a result, it learned to associate male faces with the concept of ‘person’ more than female faces.
This kind of algorithmic bias can have a severe impact on the real world, as it can lead to women being denied access to certain services or being treated differently by law enforcement.
Data bias
Another issue with AI is that it often relies on data that is biased. This can be due to the fact that the data is collected in a biased way or because it reflects the biases that exist in the real world.
For example, a study conducted by Ellen Broad, an expert in data sharing, infrastructure and ethics, found that Google Photos image recognition system is more likely to label pictures of black people as ‘gorillas’ than pictures of white people. This is because the system had been trained on a dataset that was predominantly white. As a result, it learned to associate black faces with the concept of ‘gorilla’ more than white faces. This kind of data bias can lead to AI systems making inaccurate and potentially harmful decisions. For example, if a facial recognition system is more likely to misidentify black people as criminals, then it could lead to innocent people being wrongly arrested.
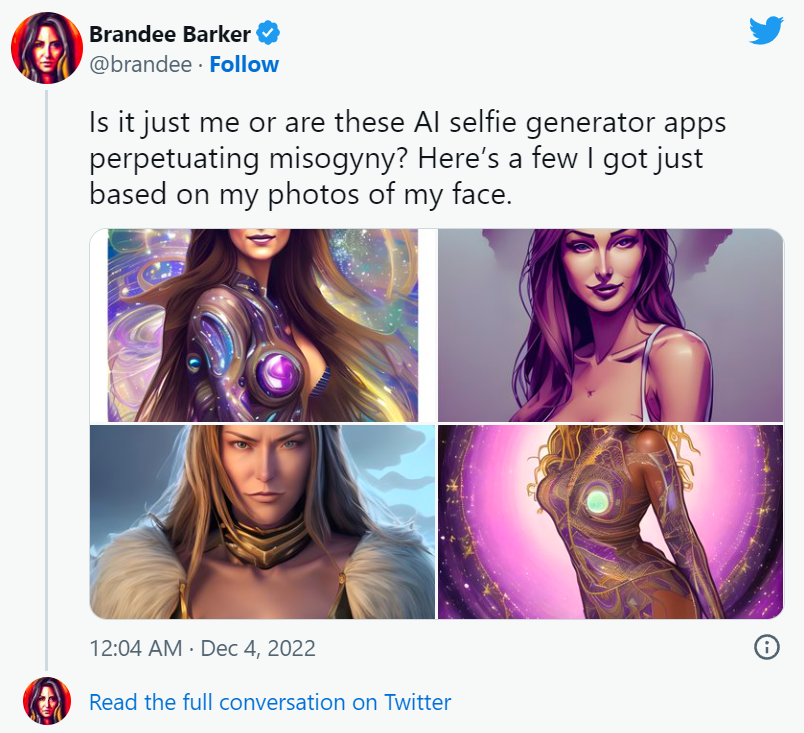
Moreover there’s something deeply troubling about the way AI is being used to create ‘portraits’ of people, particularly women. In the case of Brandee Barker, an AI created deeply sexualized versions of the woman.
This isn’t just a case of bad taste or something that can be chalked up to the ‘uncanny valley’ effect. There’s a more sinister element at play here: the objectification and sexualization of women by AI.
It’s not just Barker who has been rendered in a sexualized manner by AI. In an essay for Wired, the writer Olivia Snow wrote that she submitted “a mix of childhood photos and [current] selfies” to Lensa AI and received back “fully nude photos of an adolescent and sometimes childlike face but a distinctly adult body”.
The AI-generated images of women are eerily realistic, and that’s what makes them so troubling. They look like real women, but they’ve been created by machines with the sole purpose of objectifying and sexualizing them. This is a scary prospect, because it means that AI is perpetuating and amplifying the misogyny that already exists in our society.
Addressing the issue
Given the potential impacts of AI-perpetuated misogyny, it is important that the issue is addressed. The solution to this problem is not to try to create AI that is gender-neutral. Instead, we need to ensure that AI systems are designed and built with the needs of all users in mind. This includes ensuring that a diverse range of voices are involved in the development process and that training data is representative of the real world. Only by taking these steps can we create AI systems that are truly inclusive and beneficial for everyone.
Sources:
Lensa AI app
https://www.theguardian.com/us-news/2022/dec/09/lensa-ai-portraits-misogyny
https://news.mit.edu/2018/study-finds-gender-skin-type-bias-artificial-intelligence-systems-0212
