
On Sunday night, the biggest film event took place in LA, albeit in a much different format than usual. Not only did the ceremony take place at a different venue (no Dolby Theater this time), but also it was a much smaller affair, with many attendees connecting through Zoom and with those inside the venue following social distancing protocols. While the ceremony might have looked different, it was still a celebration of the movie industry at its finest, which like virtually all other sectors took a hit in 2020. Let us take a look at the ceremony through a tech lens (which I hope is not the first thing which popped into your mind when thinking about the Oscars).
Source: LA Times
If you weren’t already aware, betting on which nominees are going to take the shiny statue home that night is a pretty big deal (and a lucrative business, might I add), with odds being taken as soon as the nominations come through. With lots of historical data readily available, it is no surprise that machine learning algorithms have started to be deployed to predict just who will be crowned the winner during the ceremony.
One such attempt was made on a blog called BigML, where predictions were made for 8 main categories at the Oscars. For each separate category, different models were trained, which were fed historical data (previously nominated and victorious movies at the Oscars), but also information regarding the movies’ evaluation on IMDB, nominations and winners for 20 key industry awards (Golden Globes, BAFTAS, Critics Choice etc.), as well as basic information such as synopsis, duration, budget and genre. The whole dataset consisted of over 1k entries, with over a 100 features.
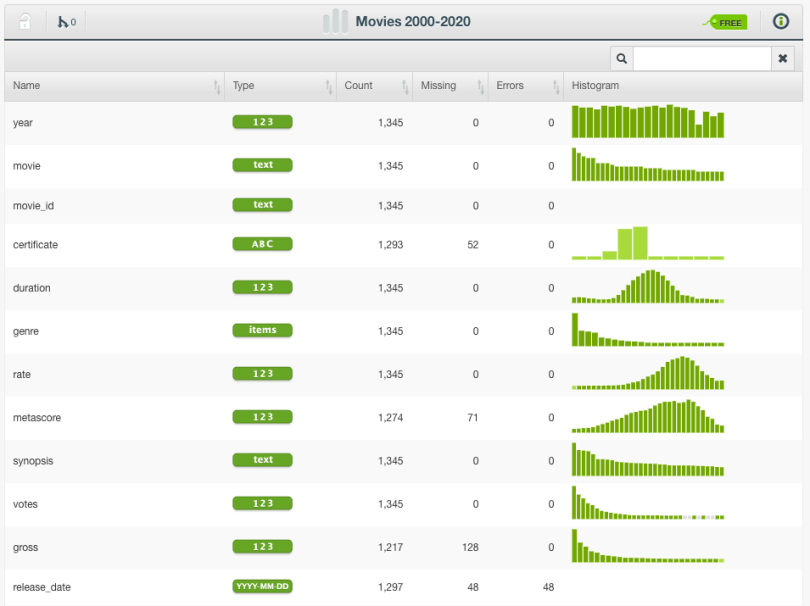
Overview of the dataset. Source: BigML blog
The 8 different models were trained with multiple approaches on BigML side, with a variety of their own products used in the process, which consisted of supervised learning algorithms solving classification and regression and optimization process for model selection and parameterization. Once the candidate models were created, Batch Predictions were made against the movies produced in 2020 that we had set aside in a separate dataset. As was the case last year, all approaches yielded more or less similar predictions supporting each other’s constructs. The individual Deepnets models configured with the Automatic Network Search option were chosen in the end.
For reference, the field importance report below is that of the Best Picture Oscar and it shows that fields like user reviews, synopsis, votes, and wins in Critic’s Choice plus nominations for Online Film Critics Society, People’s Choice, Hollywood Film, and BAFTA awards all factored in strongly in the final scores for each Best Picture nominee.
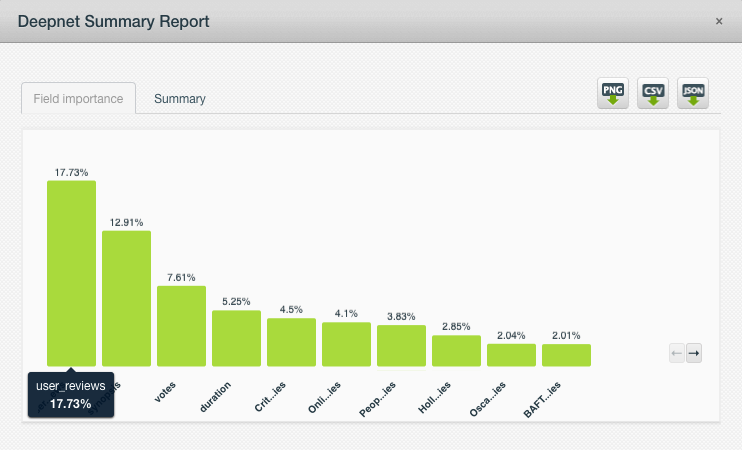
Best Picture Deepnet summary report. Source: BigML blog
As was mentioned, BigML considered 8 categories, and the models created by them turned out to be right in 4 out of 8 cases – the models correctly predicted the victors in Best Picture, Best Director, Best Supporting Actress and Best Supporting Actor categories. While it definitely could be better, it correctly predicted the win for Nomadland in the Best Picture category, which is the hardest one of them all to get right (due to a different process of selecting the winner called preferential balloting).
Speaking of the process of selecting the winner through preferential balloting, an article by Nicholas Parker written in 2020 is worth mentioning, where the method was clearly explained, and where the author created a bespoke algorithm mimicking the unique voting method. Using the example of 2020 Oscar nominees, Parker trained his own model utilising scraped data for each awards show’s (from the ‘award season’, such as Golden Globes or BAFTAS) nominees and winners from Wikipedia, and historical wins at the Oscars of the Best Picture category. He then merged them all into one dataset in Python using the Pandas and Beautiful Soup packages.
Preferential balloting at the Oscars is a system where voters submit a ballot of all the nominees ranked from “best to worst”. Once the ballots are collected, each first choice on a ballot is tallied up as a vote for that particular movie. Then the least popular films are eliminated one by one, and ballots are once again ranked, until one film has greater than 50% of the #1 votes. After a film is eliminated from all ballots, the ballots which previously had the eliminated film at their #1 spot, now have their #2 move to the top spot, which increases the number of votes for the remaining films. This process continues until one film has greater than 50% of the #1 votes and then it is declared the winner. A simulation of this elimination process is shown below.
Simulation of preferential balloting elimination. Source: Towards Data Science
Parker then went on to use a Random Forest Classifier, where the ProbA values for each film were used in the test set, and then further used to create 1st – 9th place ranking of the film.

An overview of an Individual Decision Tree’s vote on the test. Source: Towards Data Science
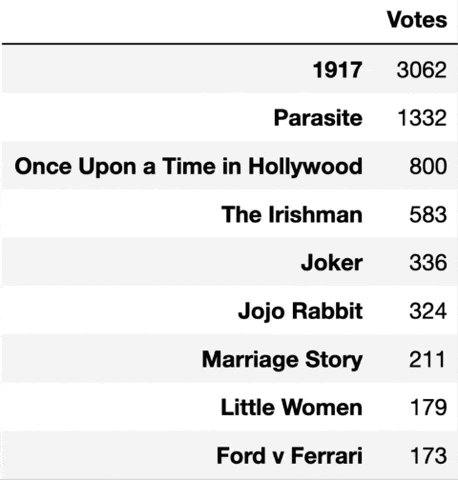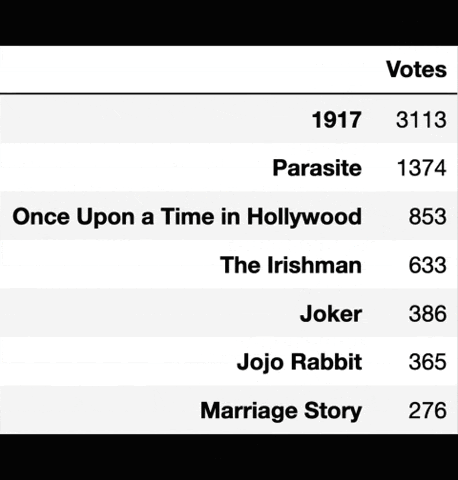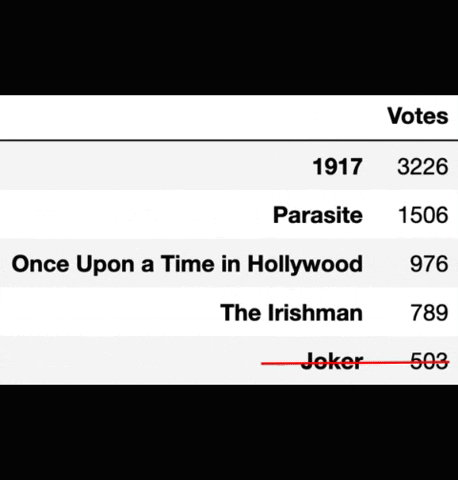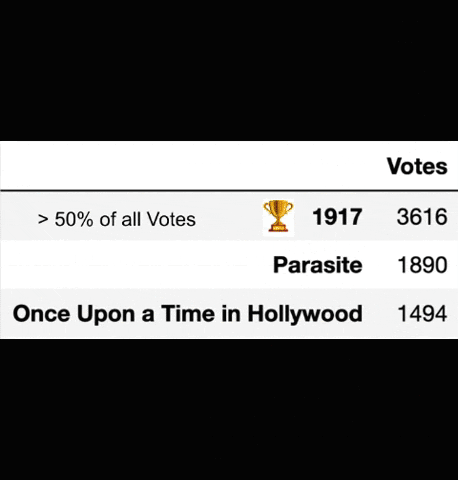
In Parker’s own words: “Using my Preferential Balloting Random Forest I simulated this year’s Best Picture race. To de-correlate each Decision Tree, I varied which awards show each tree saw, similar to Random Forest’s max_featureshyperparameter. In this simulation, max_features represents what guild the voting academy member may be in, or how closely they follow the other awards shows that season. I also included a random noise feature for each Decision Tree to train on, representing each voter’s innate bias towards certain films. The Academy is made up of around 7,000 unique voters, so I fired up my Forest, which soon produced 7,000 ballots”. His final predictions looked like this, with 1917 being crowned the winner:
The final results after 6 rounds of preferential balloting elimination. Source: Towards Data Science
While Parker did not predict the winner correctly – the big prize went to Parasite that night, the movie was the second choice of the algorithm, meaning that Parker was definitely on to something! Anyways, the process itself is super fascinating to watch, and as we can see the results were super close to reality.
I hope this technological perspective at the Oscars was also as intriguing to you all as it was to me, and that they inspired you to look deeper for tech related issues in the most surprising of places.
Sources: