

Training and neural networks
The training process is typically performed using a technique called backpropagation. In backpropagation, the LLM is given a sequence of words as input and it produces a sequence of words as output. The LLM’s output is then compared to the desired output, and the LLM’s parameters are adjusted to reduce the error between the two outputs.
This process is repeated over and over again, until the LLM is able to predict the next word in the sequence with a high degree of accuracy.
The neural network architecture that is most commonly used for LLMs is the transformer neural network. Transformer neural networks are able to model long-range dependencies in sequences, which is essential for many NLP tasks.
Transformer neural networks work by using a self-attention mechanism. Self-attention allows the LLM to learn relationships between different parts of the input sequence, without having to process the sequence sequentially.
This makes transformer neural networks very efficient and effective for training LLMs.
Once the LLM is trained, it can be used to perform a variety of tasks, such as:
-Generating text
-Translating languages
-Answering questions
-Writing different kinds of creative content

Probability Distrybiution
LLM uses a probability distribution over the next word in the sequence. This probability distribution is calculated using the LLM’s parameters and the previous words in the sequence.
The LLM then generates the next word by sampling from this probability distribution.
Here is a simplified example of how an LLM might generate text:
-The user provides the LLM with a prompt, such as “Write a poem about a cat.”
-The LLM generates the first word of the poem by sampling from a probability distribution over the next word in the sequence.
-The LLM then generates the second word of the poem by sampling from a probability distribution over the next word in the sequence, given the first word of the poem.
-The LLM repeats this process until it reaches the end of the poem.
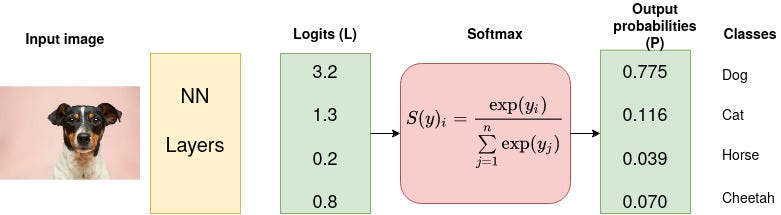
Softmax function (probability calculation)
There are a few reasons why the softmax function is commonly used in large language models (LLMs) to calculate the probability distribution over the next word in the sequence:
– The softmax function ensures that the probabilities sum to 1. This is important for tasks such as classification and prediction, where we want to know the probability that a given input belongs to a particular category.
– The softmax function is easy to compute. This is important for LLMs, which need to be able to generate text in real time.
– The softmax function is well-behaved mathematically. This makes it easy to train and deploy LLMs.
Some other probability distribution tools, such as the sigmoid function and the hyperbolic tangent function, do not have all of these advantages. For example, the sigmoid function does not ensure that the probabilities sum to 1. The hyperbolic tangent function is more difficult to compute than the softmax function.
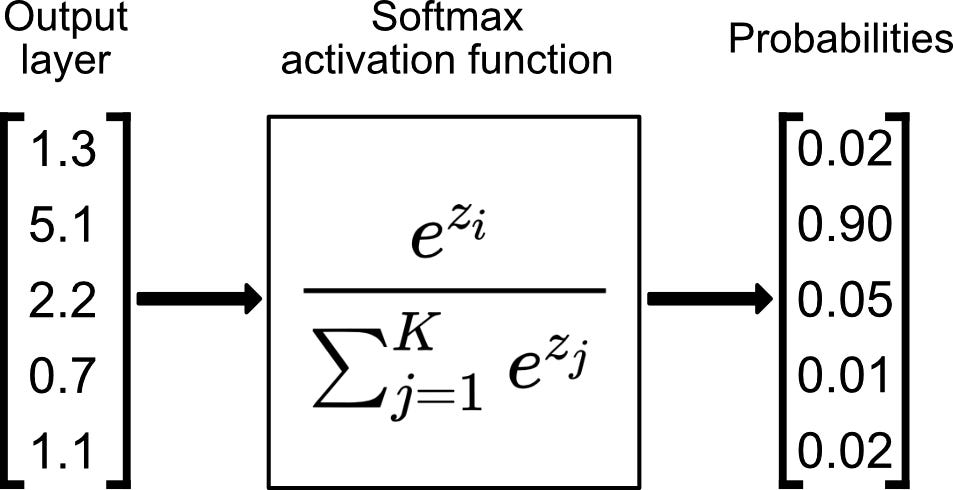
softmax:
https://deepai.org/machine-learning-glossary-and-terms/softmax-layer
https://en.wikipedia.org/wiki/Softmax_function
Transformer NN
https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)
Backpropagation
https://en.wikipedia.org/wiki/Backpropagation
I used Bard. Prompts: “Make this blog post more organized and coherent: ”, “why is Softmax commonly used in large language models”, “give me an example of how probability distribution work”
If you want to do your own research there is a great series on wikipedia about AI that includes all the knowlage you need to understand the process behind this technology.
pictures
https://webz.io/wp-content/uploads/2023/03/Large-Language-Models-01-830×363.jpg.webp
https://d2l.ai/_images/transformer.svg
https://miro.medium.com/max/781/1*KvygqiInUpBzpknb-KVKJw.jpeg
https://towardsdatascience.com/softmax-activation-function-explained-a7e1bc3ad60



{kind=link}